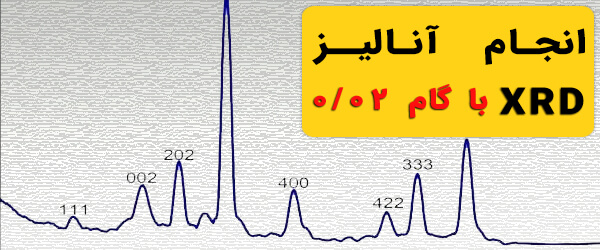
-

-
خدمات آنالیز
- آنالیزهای طیف سنجی
- آنالیزهای میکروسکوپی
- آنالیزهای عنصری
- آنالیزهای الکتروشیمیایی
- آنالیزهای فیزیکی
- آنالیزهای کروماتوگرافی
- آنالیزهای شیمی تر و تیتراسیون
-
آنالیزهای سلولی، میکروبیولوژی و ژنتیک
-
روش های آماده سازی و تصویربرداری
- خدمات فریزدرایر (خشک کن انجمادی - Freeze dryer)
- میکروسکوپ کانفوکال (Confocal)
- خدمات تصویربرداری فلورسانت و رنگ آمیزی
-
آنالیزهای آنتی باکتریال
- آزمون آنتی باکتریال تعیین MIC و MBC
- آزمون آنتی باکتریال تعیین هاله عدم رشد (Disk diffusion)
- آزمون بررسی میزان آنتی باکتریال کالاهای نساجی (پارچه ها)
- بررسی خاصیت ضد قارچی پارچه ها
-
آنالیزهای مطالعه پروتئین ها و DNA
- Real Time PCR
- خدمات الکتروفورز افقی و عمودی
- خدمات SDS-PAGE
- آزمون برادفورد (سنجش کمی پروتئین ها)
- استخراج DNA از باکتری ها
- استخراج RNA
- سنتز cDNA
-
آنالیزهای سلولی برون تنی (In-Vitro)
- آزمون سمیت شناسی به روش MTT
- آزمون چرخه سلولی با فلوسایتومتری
- ارزیابی ROS با فلوسایتومتری
- ارزیابی سلول های آپاپتوتیک و نکروتیک به روش Annexin V-FITC/PI
- ارزیابی فعالیت کاسپازهای مختلف در رده سلولی
- اندازه گیری میزان نیتریک اکساید NO
- ارزیابی ظرفیت آنتی اکسیدانی به روش رادیکال DPPH
-
- آنالیز سنگ، خاک و مواد معدنی
-
آنالیزهای متالورژی و خواص مکانیکی مواد
-
آنالیزهای غیر مخرب
- تست RT
- تست PT
- تست MT
-
آنالیزهای متالورژی و خوردگی
- خوردگی SCC
- خوردگی HIC
- آزمون متالوگرافی
- آزمون سالت اسپری
- عملیات حرارتی
- آسیاب گلوله ای سیاره ای
-
آزمون های خواص مکانیکی مواد
- آزمون کشش
- آزمون فشار
- آزمون خمش
- آزمون های سختی سنجی
- آزمون ضربه
- اسپین تست
-
-
آنالیزهای آب
-
آنالیزهای خاک
- تعیین مش بندی مواد با الک
- اندازه گیری کلراید در عصاره اشباع خاک
- اندازه گیری pH در عصاره اشباع خاک
- درصد اشباع خاک
- درصد اولیه رطوبت خاک
- شناسایی بافت خاک
- تعیین چگالی مواد
- اندازه گیری EC در عصاره اشباع خاک
- اندازه گیری سولفات در عصاره اشباع خاک
- اندازه گیری سدیم در عصاره اشباع خاک
- اندازه گیری پتاسیم در عصاره اشباع خاک
- اندازه گیری منیزیم در عصاره اشباع خاک
-
آنالیزهای صنایع غذایی
- آنالیز چربی (سوکسله)
- اندازه گیری چربی لبنیات با روش ژربر
- آزمون اندازه گیری کربوهیدرات ها در مواد خوراکی
- آزمون بریکس در ۲۰ درجه سلسیوس
- اندازه گیری TVN مقدار ازت فرار
- اندازه گیری پراکسید چربی
- اندازه گیری نمک در مواد غذایی
- اندازه گیری خاکستر مواد غذایی
- اندازه گیری رطوبت در مواد غذایی
- سنجش پروتئین در مواد غذایی
-
آزمایشات میکروبیولوژی مواد غذایی
- آنالیز کپک و مخمر
- شناسایی اشرشیاکلی در مواد غذایی
- شناسایی تخم انگل در میوه و سبزیجات
- تشخیص استافیلوکوک های گواکولاز مثبت به روش MPN
- شمارش اسپور باکتری ها (هوازی و بی هوازی)
- تشخیص سالمونلا در مواد غذایی
- جداسازی باکتری های مزوفیل و ترموفیل
- تشخیص کلی فرم در مواد غذایی
- اندازه گیری فلزات سنگین در مواد غذایی
-
خدمات بخش بیوشیمی و عصاره گیری
-
خدمات بخش بیوشیمی و عصاره گیری
- ارزیابی ظرفیت آنتی اکسیدانی به روش رادیکال DPPH
- خدمات عصاره گیری با سوکسله
- عصاره گیری به روش ماسراسیون یک گیاه
-
- آنالیزهای روغن های صنعتی
-
خدمات تحلیل و تفسیر آنالیزها
- تحلیل نتایج و تفسیر آنالیز XRD
- تحلیل و تفسیر نتایج آنالیز FTIR
- تحلیل و تفسیر نتایج آنالیز DRS
- تحلیل و تفسیر نتایج آنالیز BET
- رسم نمودار هیستوگرام و تعیین سایز ذرات TEM/SEM
- تحلیل و تفسیر نتایج میکروسکوپ HR-TEM
- تحلیل و تفسیر نتایج آنالیز XPS
- تحلیل و تفسیر نتایج آنالیز DLS
- تحلیل و تفسیر نتایج آزمون سمیت شناسی MTT
- تحلیل و تفسیر نتایج آنالیز NMR
- خدمات شناسایی انواع مواد
- خدمات فرآوری مواد معدنی
- تعرفه خدمات
- آکادمی مهامکس
- درباره مهامکس
تخفیفهای لبزنت
انجام پروژه های یادگیری ماشین Machine learning
یادگیری ماشین یا ماشین لرنینگ یا (ML) Machine Learning از پرکاربردترین حوزه ها در هوش مصنوعی است که در بسیاری از صنایع و رشته ها کاربرد قابل توجهی پیدا کرده است. استفاده از آن در بسیاری شرکت های تجاری و صنایع و تحقیقات دانشگاهی کاربرد دارد و پروژه های بسیاری در این خصوص تعریف شده است. در ماشین لرنینگ، ماشین بر اساس تجربه خود و به صورت کاملا مستقل و جدای از برنامه ریزی انسان پیشرفت می کند. این امر می تواند در پیش بینی شرایط آینده بسیار موثر باشد. در صورتی که یک شرکت تجاری هستید و می خواهید برای اهداف مالی خود از یادگیری ماشین استفاده کنید و با محقق دانشگاهی هستید و برای پروژه درسی، سمینار یا مقطع خود می خواهید از ماشین لرنینگ کمک بگیرید می توانید سفارش خود را برای مهامکس ثبت نموده تا پروژه شما با بالاترین کیفیت انجام شود. همچنین این امکان وجود دارد تا در صورت درخواست آموزش های لازم نیز به شما برای ارائه پروژه خود داده شود.
مشخصات دستگاه های آماده برای ارائه خدمات انجام پروژه های یادگیری ماشین Machine learning
درباره آنالیز
انجام پروژه های یادگیری ماشین Machine learning
یادگیری ماشین یا ماشین لرنینگ یا (ML) Machine Learning یکی از برنامه های بسیار کاربردی در حوزه هوش مصنوعی است که امروزه در بسیاری از صنایع و رشته ها کاربرد قابل توجهی پیدا کرده است. حوزه کاربردی ماشین لرنینگ، مراکز تجاری و فروش تا تحقیقات دانشگاهی و انواع رشته ها (از رشته های علوم زیستی و علوم پایه تا انواع رشته های مهندسی و انسانی) را در بر می گیرد. در نتیجه تقاضاهای شرکت های تجاری و پروژه های دانشگاهی مرتبط با حوزه یادگیری ماشین برای انجام پروژه یادگیری ماشین نیز شدیدا افزایش یافته است. در مهامکس متخصصان با تجربه در حوزه ماشین لرنینگ در کنار شما هستند. در صورتی که یک شرکت تجاری هستید و می خواهید برای اهداف مالی خود از یادگیری ماشین استفاده کنید و یا محقق دانشگاهی هستید و برای پروژه درسی، سمینار یا مقطع خود می خواهید از ماشین لرنینگ کمک بگیرید می توانید سفارش خود را برای مهامکس به عنوان یکی از قدیمی ترین و شناحته شده ترین مراکز آنالیزهای علمی کشور، ثبت نموده تا پروژه شما با بالاترین کیفیت انجام شود. همچنین این امکان وجود دارد تا در صورت درخواست آموزش های لازم نیز به شما برای ارائه پروژه خود داده شود.
در یادگیری ماشین، سیستم ها بر اساس تجربه خود و به صورت مستقل و جدای از برنامه ریزی انسانی می توانند پیشرفت کنند. در حقیقت ماشین داده ها را درک کرده از خود یاد می گیرد! این امر می تواند در پیش بینی شرایط آینده بسیار موثر باشد. در زبان های برنامه نویسی معمول، ما دستورالعمل هایی را به سیستم می دهیم و سیستم از آنها پیروی می کند. در ماشین لرنینگ مجموعه ای از مثال ها را به سیستم می دهیم و ماشین خودش ظیفه خود را پیدا می کند. به عنوان مثال به جای تعریق ویژگی های گربه ها به سیستم، عکس هزاران گربه را به سیستم می دهیم و هود ماشین ویژگی های گربه ها را درک کرده و از این بعد می تواند گربه ها را تشخیص دهد. برای آموزش ماشین و انجام پروژه های یادگیری ماشین عموما از زبان نرم افزاری پایتون و سپس از زبان های R و یا مطلب استفاده می شود.
در فرآیندهای داده کاوی حجم زیادی از اطلاعات و داده ها گردآوری می شوند. سپس ماشین در ماشین لرنینگ داده ها را تحلیل کرده و الگوهایی را بدست آورده و آنها را به سیستم آموزش می دهد تا بعدا سیستم از آنها استفاده کند. تکنیک های گوناگونی به منظور درک و آموزش این الگوها و الگوریتم ها در Machine Learning وجود دارد. هر کدام از این تکنیک ها نقاط ضعف و قوت خودشان را دارند. البته این نقاط مربوط به نوع داده ها نیز می باشد. داده ها عموما یا برچسب دارند یا ندارند. در حالتی که داده ها برچسب داشته باشند، داده دارای ورودی و خروجی مشخص بوده و داده برای ماشین به صورت کامل خوانا است. در حقیقت داده های برچسب گذاری شده از قبل دارای طبقه بندی و اطلاعات متمایز هستند. این داده ها یا آموزشی اند (که مدل را برای سیستم آموزش می دهند) و یا آزمایشی اند (برای ارزیابی اولیه سیستم). برچسب گذاری در مرحله ای پیش از معرفی داده توسط انسان انجام می شود. اگر داده برچسب نداشته باشد، ماشین نمی تواند آنرا بخواند و باید از راه حل های پیچیده تر استفاده کرد. در حقیقت در داده های بدون برچسب، خود ماشین باید ویژگی ها را استخراج کرده و دسته بندی کند.
در اولین گام از ماشین لرنینگ باید داده ها را به ماشین داد. این داده ها از منابع مختلفی بدست می آیند. می توانند متنی، صوتی و یا تصویری باشند. قالب داده ها باید مناسب باشند. به طور مثال به صورت فایل CSV یا یک database. مرحله بعدی انتخاب مدل یادگیری ماشین است. به صورت کلی سه دسته تکنیک یادگیری اصلی وجود دارد: یادگیری با نظارت. بدون نظارت و یادگیری تقویتی. در مدل یادگیری تحت نظارت که از مهمترین روش های ماشین لرنینگ است، فرآیند آموزش بر روی ورودی هایی که برچسب دارند صورت می گیرد. این تکنیک از قوی ترین روش های یادگیری است. الگوریتم ماشین لرنینگ در حالت نظارت شده، مجموعه و بسته ای از داده های آموزشی در دسترس دارد. این بسته بخشی از داده ها است که مجموعه بزرگتر را تشکیل می دهند. داده آموزشی در واقع ایده ای مشکل، راه هایی برای رفع آن و بهش هایی که باید به آنها رسیدگی شود را معرفی می کند. خصوصیات این داده آموزشی شبیه به داده های نهایی باید باشد. هنگامی که الگوریتم داده را می گیرد، روابطی را بین آنها بدست آورده و یک ارتباط علت و معلولی مابین متغییرها پدید می آورد. از این روابط به عنوان یک راه حل استفاده می شود.
انواع روش های ML تحت نظارت
Machine Learning دارای الگوریتم های متعددی است. در حوزه الگوریتم های دسته بندی در یادگیر یهای تحت نظارت، مدل های زیر را می توان از مهمترین انها در نظر گرفت.
الگوریتم جنگل تصادفی: این نوع الگوریتم به خصوص در موارد دسته بندی و پیش بینی به کار برده می شود. در این نوع الگوریتم، چند درخت تصمیمی با هم ترکیب می شوند. این درخت ها به صورت جداگانه آموزش می بیند.خروجی تمام درخت ها سپس با هم ترکیب شده و به منظور پیش بینی مورد استفاده قرار می گیرد. برای مسئله های پیش بینی عموما از میانگین و در مسئله های دسته بندی، معمولا از جامعه اکثریت استفاده می شود.
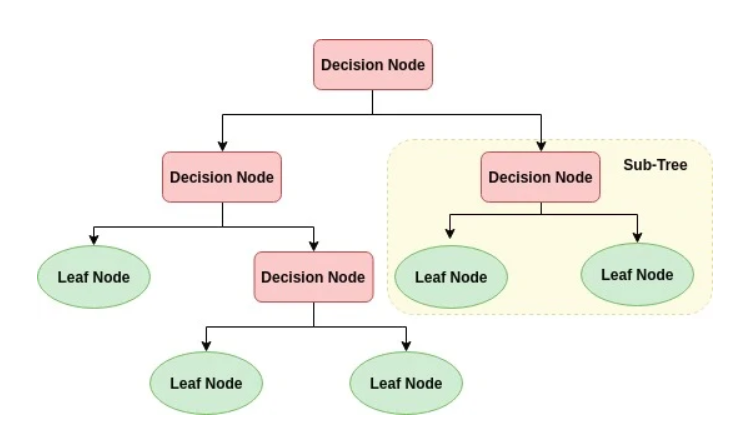
الگوریتم درخت تصمیم: این الگوریتم نیز عموما برای مسائل دسته بندی و پیش بینی مورد استفاده قرار می گیرد. این مدل درخت سلسه مراتبی از شرایط و تصمیم ها است. به این معنا که در هر گره، یکی از شروطی یا تصمیم ها یا سوالات وجود دارد. بر پایه جوابی که در گره داده می شود به سمت یکی از گره های فرزند هدایت می شویم. در نهایت این پروسه ادامه پیدا می کند تا به یک گره پایانی و یا برچسب پایانی برسیم. در شکل زیر به صورت شماتیک این مدل را مشاهده می کنید.
الگوریتم رگرسیون لجستیک: این نوع الگوریتم عموما برای مسئله های دسته بندی به کار برده می شود. اگر چه کاربرد اصلی آن برای دسته بندی های دوتایی است ولی می توان آنرا برای چند دسته ای ها نیز به کار برد. در این مدل الگوریتم، یک تابع لجستیک ساخته می شود که در نتیجه آن امکان روی دادن یک واقعه مربوط بودن به یک دسته را بر پایه ویژگی های ورودی بدست آید.
الگوریتم بردار پشتیبان: این مدل از الگوریتم بیشتر برای دسته بندی و رگرسیون مورد استفاده قرار می گیرد. در این نوع یک همه گیر دسته بندی در حالتی که بیشترین مارجین ایجاد شود، ایجاد می شود. در این مدل در نهایت داده ها به فضای ویژگی ها انتقال می یابند.
الگوریتم بیز ساده: در این الگوریتم از قواعد بیز و احتمالات استفاده می شود. این روش از الگوریتم هایی است که به عنوان ساده از آنها یاد می شود. دلیل ان این است که در آن ساده سازی شده است. چنانچه از تاثیر یک ویژگی بر ویژگی دیگر صرف نظر شده است.
ML بدون نظارت
در این دسته از الگوریتم ها، داده از طریق ماشین برای درک و یافتن الگوها بررسی و مطالعه می گردند. برخلاف روش های تحت نظارت، هیچ دستورالعمل یا کلید پاسخی به سیستم داده نمی شود. خود ماشین است که در این روش ها همبستگی ها و روابط را پیدا می کند. از طریق روابط ماشین ساختار داده ها را توصیف می نماید. به عنوان مثال از طریق دسته بندی، ماشین داده ها را سازماندهی تر می کند. با بررسی داده های بیشتر، درک ماشین از داده ها بیشتر شده و قدرت آن برای تصمیم گیری بیشتر می شود. همانگونه که بیان شد در این گونه از الگوریتم ها از داده های بدون برچسب استفاده می شود. نیازی نیست داده ها توسط اپراتور خوانده شوند. در نتیجه می توان میزان داده بسیار بیشتری به ماشین داد.
ML تقویتی
در این دسته از الگوریتم ها در حقیقت از روشی که انسان ها برای یادگرفتن استفاده می کنند، الهام گرفته شده است. ماشین پس از تعریف انواع قانون ها، احتمالات گوناگون را بررسی می کند. سپس نتایج را بررسی می کند که کدامیک از آنها بهینه می باشد. در الگوریتم های تقویتی، در حقیقت ماشین آزمون و خطا می کند. ماشین حتی در این روش ها از تجربیات خود نیز درس می گیرد و خود را بهبود می دهد. خروجی که مناسب نباشد به گونه مجازات می شود و آنهایی که مطلوب اند تقویت می گردند.
پس از آموزش مدل، باید مدل را ارزیابی کرد. این امر از طریق دادن داده های جدید عموما انجام می شود. ممکن است بعد از آن نیاز به بهبود و بهینه سازی مدل باشد. در نهایت مدل آمده پیش بینی داده ای جدید است.
کاربردهای ماشین لرنینگ
حوزه کاربردهای ماشین لرنینگ بسیار وسیع است. در زیر به چند حوزه کاربردی اشاره می شود.
- حوزه بهداشت و درمان: دارو پژوهشی و کشف داروهای جدید، توسعه درمان های شخصی سازی شده، توسعه حسگرهای دستگاه های تناسب اندام و گجت های پوشیدنی.
- حوزه های مالی: تشخیص تقلب ها، حوزه سابری و شناسایی فرصت های سرمایه گذاری.
- بخش فروشگاهی: دسته بندی مشتریان، پیشنهاد به مشتریان و بازاریابی.
- صنعت گردشگری
- رسانه های اجتماعی
انجام پروژه های یادگیری ماشین
جهت انجام پروژه یادگیری ماشین خود ابتدا باید درخواست خود را در همین صفحه ثبت نمایید. کارشناسان ما درخواست شما را بررسی کرده و در صورت لزوم با شما در تماس خواهند بود. سپس هزینه و زمان لازم برای انجام پروژه مشخص می شود. هزینه و زمان انجام طرح بیش از هر موردی به این بستگی دارد که داده ها یا دیتابیس طرح در دسترس است یا باید استخراج شود. در حقیقت سنگین ترین بخش پروژه نیز این مرحله است. در نهایت پس از انجام پروژه، در صورتی که درخواست آموزش داشته باشید، آموزش های لازم به شما داده می شود و پروژه تحویل می گردد. نگران نباشید! در طول انجام طرح همواره از پشتیبانی کارشناسان ما برخوردار هستید.